基于Ubuntu22.04部署bcache模式ceph
基于Ubuntu22.04部署bcache模式ceph
Yeliang Wu
已于 2023-08-01 12:49:40 修改
基于Ubuntu22.04部署bcache模式ceph
Yeliang Wu
已于 2023-08-01 12:49:40 修改
阅读量2.4k
收藏 6
点赞数
分类专栏: ceph 文章标签: ceph bcache osd ubuntu mds
版权
ceph
专栏收录该内容
20 篇文章
订阅专栏
作者:吴业亮
博客:wuyeliang.blog.csdn.net
将Bcache集成到Ceph OSD后端可以带来一些优点和潜在的缺点。以下是它们的一些方面:
优点:
提高性能:BCache作为SSD缓存设备,可以提供更快的数据读取和写入速度。通过将热门数据缓存在SSD上,可以减少对慢速磁盘的访问,从而改善存储系统的整体性能。
提高响应性:使用BCache作为缓存层可以显著减少IO延迟,因为SSD具有更快的随机访问时间,响应时间更短。
灵活性:BCache可以根据应用程序的需求进行配置和调整。可以设置不同的缓存规则和策略,根据数据的访问模式来调整数据在SSD上的缓存策略,以最大程度地提高性能。
成本效益:通过将较便宜的磁盘与SSD缓存结合,可以在提供高性能和低成本的存储方案之间取得平衡。
缺点:
部署和管理复杂性:集成BCache到Ceph OSD后端需要额外的配置和管理。这可能增加了部署和管理方面的复杂性,并需要更多的知识和技能。
可靠性考虑:BCache是一个缓存层,它依赖于底层磁盘来存储数据。尽管BCache有内建的数据保护措施,但缓存设备的故障或数据丢失仍然可能导致数据损坏或不一致。
存储容量限制:由于SSD的成本较高,可能无法将所有数据都缓存在SSD上,因此需要权衡SSD缓存容量和数据存储容量之间的平衡。
重要提示:在集成BCache到Ceph OSD后端之前,请考虑系统的需求、可靠性要求、成本预算以及管理复杂性。在部署之前建议进行充分的测试和评估,以确保性能提升和可行性。此外,定期监控和维护BCache缓存设备的容量和性能是至关重要的,以确保系统的可靠性和一致性。
1、配置网络/etc/netplan/01-netcfg.yaml
network:
ethernets:
# interface name
ens18:
dhcp4: false
# IP address/subnet mask
addresses: [172.16.8.202/24]
# default gateway
# [metric] : set priority (specify it if multiple NICs are set)
# lower value is higher priority
routes:
- to: default
via: 172.16.8.1
metric: 100
nameservers:
# name server to bind
addresses: [8.8.8.8]
# DNS search base
#search: [srv.world,server.education]
dhcp6: false
version: 2
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
生效
# netplan apply
1
修改主机名
hostnamectl set-hostname node3
1
修改/etc/hosts
# cat /etc/hosts
127.0.0.1 localhost
127.0.1.1 ubuntu
172.16.8.201 node1
172.16.8.202 node2
172.16.8.203 node3
# The following lines are desirable for IPv6 capable hosts
::1 ip6-localhost ip6-loopback
fe00::0 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
1
2
3
4
5
6
7
8
9
10
11
12
13
安装docker
apt -y install docker.io
1
更新国内源
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy main restricted universe multiverse
# deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy-updates main restricted universe multiverse
# deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy-updates main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy-backports main restricted universe multiverse
# deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy-backports main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy-security main restricted universe multiverse
1
2
3
4
5
6
7
更新ceph国内源
wget -q -O- 'https://download.ceph.com/keys/release.asc' | sudo apt-key add -
sudo apt-add-repository 'deb https://mirrors.tuna.tsinghua.edu.cn/ceph/debian-quincy/ buster main'
sudo apt update
源地址:
https://satishdotpatel.github.io/deploy-ceph-storage-using-cephadm/
1
2
3
4
5
安装cephadm
apt update
apt install -y cephadm
1
2
针对ssd分区
parted -s /dev/sdf mklabel gpt
parted /dev/sdf mkpart primary xfs 00.0GB 10.0GB
parted /dev/sdf mkpart primary xfs 10.0GB 20.0GB
parted /dev/sdf mkpart primary xfs 20.0GB 30.0GB
parted /dev/sdf mkpart primary xfs 30.0GB 40.0GB
parted /dev/sdf mkpart primary xfs 40.0GB 50.0GB
parted /dev/sdf mkpart primary xfs 50.0GB 60.0GB
parted /dev/sdf mkpart primary xfs 60.0GB 70.0GB
parted /dev/sdf mkpart primary xfs 70.0GB 80.0GB
parted /dev/sdf mkpart primary xfs 80.0GB 85.0GB
parted /dev/sdf mkpart primary xfs 85.0GB 90.0GB
parted /dev/sdf mkpart primary xfs 90.0GB 95.0GB
parted /dev/sdf mkpart primary xfs 95.0GB 100.0GB
1
2
3
4
5
6
7
8
9
10
11
12
13
# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
loop0 7:0 0 63.3M 1 loop /snap/core20/1822
loop1 7:1 0 111.9M 1 loop /snap/lxd/24322
loop2 7:2 0 49.8M 1 loop /snap/snapd/18357
loop3 7:3 0 49.8M 1 loop /snap/snapd/18596
loop4 7:4 0 63.3M 1 loop /snap/core20/1852
sda 8:0 0 80G 0 disk
├─sda1 8:1 0 1M 0 part
└─sda2 8:2 0 80G 0 part /
sdb 8:16 0 100G 0 disk
sdc 8:32 0 100G 0 disk
sdd 8:48 0 100G 0 disk
sde 8:64 0 100G 0 disk
sdf 8:80 0 100G 0 disk
├─sdf1 8:81 0 9.3G 0 part
├─sdf2 8:82 0 9.3G 0 part
├─sdf3 8:83 0 9.3G 0 part
├─sdf4 8:84 0 9.3G 0 part
├─sdf5 8:85 0 9.3G 0 part
├─sdf6 8:86 0 9.3G 0 part
├─sdf7 8:87 0 9.3G 0 part
├─sdf8 8:88 0 9.3G 0 part
├─sdf9 8:89 0 4.7G 0 part
├─sdf10 8:90 0 4.7G 0 part
├─sdf11 8:91 0 4.7G 0 part
└─sdf12 8:92 0 4.7G 0 part
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
配置bcache盘
apt install bcache-tools -y
modprobe bcache
make-bcache -C /dev/sdf1 -B /dev/sdb --wipe-bcache
make-bcache -C /dev/sdf2 -B /dev/sdc --wipe-bcache
make-bcache -C /dev/sdf3 -B /dev/sdd --wipe-bcache
make-bcache -C /dev/sdf4 -B /dev/sde --wipe-bcache
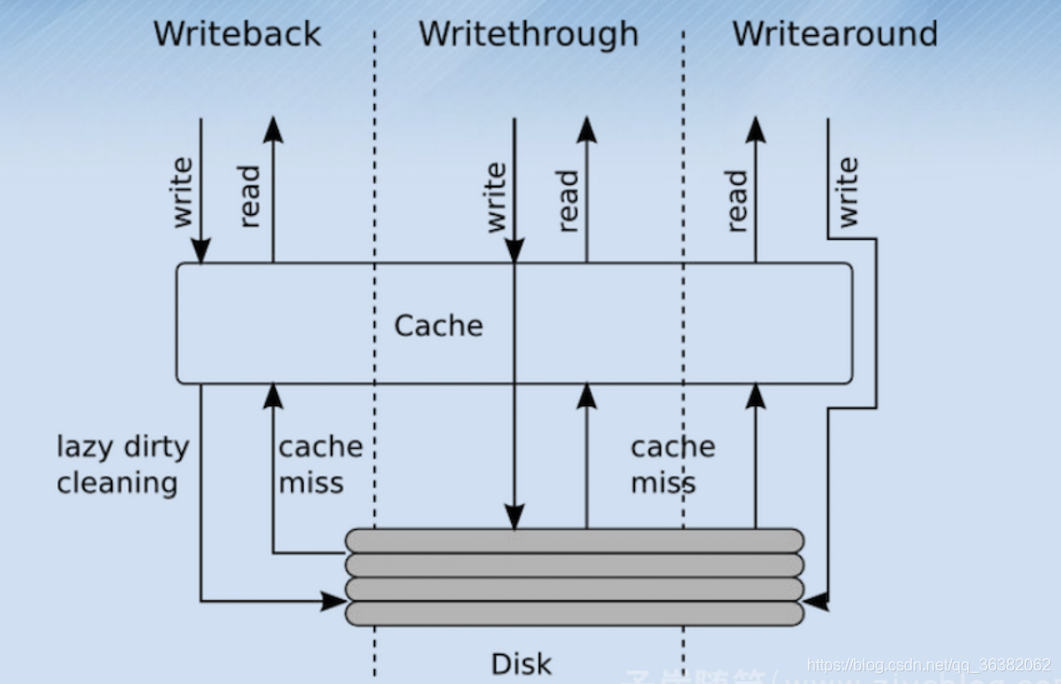
echo writeback > /sys/block/bcache0/bcache/cache_mode
echo writeback > /sys/block/bcache1/bcache/cache_mode
echo writeback > /sys/block/bcache2/bcache/cache_mode
echo writeback > /sys/block/bcache3/bcache/cache_mode
1
2
3
4
5
6
7
8
9
10
11
12
13
lvm分区
vgcreate data0 /dev/bcache0
lvcreate -l +100%FREE data0
vgcreate data1 /dev/bcache1
lvcreate -l +100%FREE data1
vgcreate data2 /dev/bcache2
lvcreate -l +100%FREE data2
1
2
3
4
5
6
7
8
安超软件包
cephadm install ceph
1
初始化集群
mkdir -p /etc/ceph
1
cephadm bootstrap --mon-ip 172.16.8.201 --allow-fqdn-hostname
1
部署单机
cephadm bootstrap --mon-ip 172.16.8.201 --allow-fqdn-hostname --single-host-defaults
1
会有如下输出
Ceph Dashboard is now available at:
URL: https://node1:8443/
User: admin
Password: 8uw3xxz9m9
Enabling client.admin keyring and conf on hosts with "admin" label
Saving cluster configuration to /var/lib/ceph/2304caa0-dd8c-11ed-b671-e93708859cab/config directory
Enabling autotune for osd_memory_target
You can access the Ceph CLI as following in case of multi-cluster or non-default config:
sudo /usr/sbin/cephadm shell --fsid 2304caa0-dd8c-11ed-b671-e93708859cab -c /etc/ceph/ceph.conf -k /etc/ceph/ceph.client.admin.keyring
Or, if you are only running a single cluster on this host:
sudo /usr/sbin/cephadm shell
Please consider enabling telemetry to help improve Ceph:
ceph telemetry on
For more information see:
https://docs.ceph.com/docs/master/mgr/telemetry/
Bootstrap complete.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
设置ceph cli
# alias ceph='cephadm shell -- ceph'
# echo "alias ceph='cephadm shell -- ceph'" >> ~/.bash_profile
1
2
ceph -s
免密设置
# ssh-copy-id -f -i /etc/ceph/ceph.pub root@node2
# ssh-copy-id -f -i /etc/ceph/ceph.pub root@node3
1
2
添加主机
# ceph orch host add node2
# ceph orch host add node3
1
2
3
查看主机
# ceph orch host ls
1
设置MGR数量
# ceph orch apply mgr 3
# ceph orch host label add node2 mgr
# ceph orch host label add node3 mgr
# ceph orch apply mgr --placement "node1 node2 node3"
1
2
3
4
删除mgr
ceph orch apply mgr “2 node1 node2 ”
1
打开 balancer 模块
# ceph balancer on
1
默认模式为 crush-compat。可使用以下方法更改模式
# ceph balancer mode upmap
1
或者
# ceph balancer mode crush-compat
1
使用 crush-compat 模式,它与旧的客户端向后兼容,并且会随着时间的推移对数据分发进行小更改,以确保 OSD 平等地使用
查看状态
ceph balancer status
1
balancer 是 Ceph Manager(ceph-mgr)的一个模块,用于优化 OSD 之间放置组(PG)放置,从而实现平衡的分发(可自动或监管方式
启用 balancer 模块
ceph mgr module enable balancer
1
启用报警模块
ceph mgr module enable alerts
1
查看
ceph mgr module ls | more
1
配置smtp
[ceph: root@host01 /]# ceph config set mgr mgr/alerts/smtp_host smtp.example.com
[ceph: root@host01 /]# ceph config set mgr mgr/alerts/smtp_destination example@example.com
[ceph: root@host01 /]# ceph config set mgr mgr/alerts/smtp_sender example2@example.com
[ceph: root@host01 /]# ceph config set mgr mgr/alerts/smtp_port 587
1
2
3
4
5
验证用户名及密码
[ceph: root@host01 /]# ceph config set mgr mgr/alerts/smtp_user admin1234
[ceph: root@host01 /]# ceph config set mgr mgr/alerts/smtp_password admin1234
1
2
设置检查周期
[ceph: root@host01 /]# ceph config set mgr mgr/alerts/interval "5m"
1
立即发送告警
[ceph: root@host01 /]# ceph alerts send
设置crash分析
通过使用 Ceph 管理器 crash 模块,您可以收集有关守护进程 crashdumps 的信息,并将其存储在 Ceph Storage 集群中,以便进一步分析。默认情况下,守护进程崩溃转储在 /var/lib/ceph/crash 中转储。您可以使用选项 crash dir 进行配置。崩溃目录按时间、日期和随机生成的 UUID 命名,包含元数据文件 meta 和最新的日志文件,其 crash_id 是相同的。
您可以使用 ceph-crash.service 自动提交这些崩溃,并在 Ceph 监控器中保留。ceph-crash.service 监视 crashdump 目录,并使用 ceph crash post 上传它们。
RECENT_CRASH heath 消息是 Ceph 集群中最常见的运行状况消息之一。此健康消息表示,一个或多个 Ceph 守护进程最近崩溃,且崩溃尚未存档或被管理员确认。这可能表示软件错误、硬件问题(如磁盘失败)或其它问题。选项 mgr/crash/warn_recent_interval 控制最近一次表示的时间周期,默认为两周。您可以运行以下命令来禁用警告
确定启用了crash
ceph mgr module ls | more
1
元数据文件是存储在 crash dir 中作为 meta 的 JSON blob。您可以调用 ceph 命令 -i - 选项,该选项会从 stdin 读取
ceph crash post -i meta
1
出所有新的以及归档的崩溃信息的时间戳或 UUID 崩溃 ID
ceph crash ls
1
列出所有新崩溃信息的时间戳或 UUID 崩溃 ID
ceph crash ls-new
1
列出按年龄分组的保存崩溃信息的概述
ceph crash stat
1
查看保存崩溃的详情
ceph crash info 2022-05-24T19:58:42.549073Z_b2382865-ea89-4be2-b46f-9a59af7b7a2d
1
删除比 KEEP days 旧的已保存的崩溃:其中 KEEP 必须是一个整数。
ceph crash prune 60
1
对崩溃报告进行归档,使其不再被视为 RECENT_CRASH 健康检查,且不会出现在 crash ls-new 输出中。它会出现在 crash ls 中
ceph crash archive 2022-05-24T19:58:42.549073Z_b2382865-ea89-4be2-b46f-9a59af7b7a2d
1
记录所有崩溃报告
ceph crash archive-all
1
删除崩溃转储
ceph crash rm 2022-05-24T19:58:42.549073Z_b2382865-ea89-4be2-b46f-9a59af7b7a2d
1
部署mon
# ceph orch host label add node2 mon
# ceph orch host label add node3 mon
ceph orch apply mon --placement="3 node1 node2 node3"
1
2
3
4
5
部署mds
ceph orch host label add node1 mds
ceph orch host label add node2 mds
ceph orch host label add node3 mds
1
2
3
部署OSD
磁盘要求
该设备不能有分区。
不得挂载该设备。
该设备不得包含文件系统。
该设备不得包含 Ceph BlueStore OSD。
该设备必须大于 5 GB。
1
2
3
4
5
6
注意:
在 Red Hat Ceph Storage 6.0 中,由于已知的错误,OSD、DB 或 WAL 部署不支持预先创建的 LVM 磁盘。
从 Red Hat Ceph Storage 6.0 开始,支持预先创建的 LVM 磁盘,包括 DB 和 WAL 设备。
设置osd自动管理内存
ceph config set osd osd_memory_target_autotune true
1
创建osd
ceph orch daemon add osd node1:/dev/data0/lvol0
ceph orch daemon add osd node1:/dev/data1/lvol0
ceph orch daemon add osd node1:/dev/data2/lvol0
ceph orch daemon add osd node2:/dev/data0/lvol0
ceph orch daemon add osd node2:/dev/data1/lvol0
ceph orch daemon add osd node2:/dev/data2/lvol0
ceph orch daemon add osd node3:/dev/data0/lvol0
ceph orch daemon add osd node3:/dev/data1/lvol0
ceph orch daemon add osd node3:/dev/data2/lvol0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
高级
ceph orch apply -i /path/to/osd_spec.yml --dry-run
1
service_type: osd
service_id: osd_using_paths
placement:
hosts:
- Node01
- Node02
spec:
data_devices:
paths:
- /dev/sdb
db_devices:
paths:
- /dev/sdc
wal_devices:
paths:
- /dev/sdd
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
部署rgw
$ radosgw-admin realm create --rgw-realm=default --default
$ radosgw-admin zonegroup create --rgw-zonegroup=default --master --default
$ radosgw-admin zone create --rgw-zonegroup=default --rgw-zone=us-east-1 --master --default
$ ceph orch apply rgw default us-east-1 --placement="1 mon0"
1
2
3
4
查看状态
systemctl status ceph-* --no-pager
docker ps
ceph -s
1
2
3
安装awscli工具
apt install awscli -y
1
创建用户
# radosgw-admin user create --uid=wuyeliang --display-name=wuyeliang --access-key=wuyeliang --secret-key=wuyeliang
1
创建bucket
$ aws s3 mb s3://wuyeliang-test --endpoint-url http://node1
make_bucket: wuyeliang-test
1
2
上传文件
$ aws s3 cp /etc/hosts s3://wuyeliang-test --endpoint-url http://node0
upload: ../etc/hosts to s3://wuyeliang-test/hosts
1
2
卸载集群
cephadm rm-cluster --fsid f64f341c-655d-11eb-8778-fa163e914bcc
1
删除repo
cephadm rm-repo
1
修改参数
允许删除pool
ceph config set mon mon_allow_pool_delete true
1
设置单副本
ceph config set global osd_pool_default_size 1
1
删除pool
ceph osd pool delete ceph-rbd ceph-rbd --yes-i-really-really-mean-it